


Blog
Read More
Guide to Power Resistors
Power resistors are used to dissipate energy by converting it to heat. and are designed to maintain stable performance. Call now and request a quote today!
Read More
Guide to Ceramic Resistors
Ceramic Composition resistors are composed of a mixture of a finely ground insulator and conductor which is compressed into a cylindrical shape. Call now!
Read More
Guide to Heat Sinks
As semiconductor devices scale to smaller sizes and higher power densities, thermal management has become more challenging Call now and request a quote!
Read More
Guide to Load Banks
A load bank is a device that is intended to accurately mimic a load that a power source will see in an actual application. Call now and request a quote today!
Read More
Guide to EMI Filters
To control the effects of EMI, standards are in place internationally, for commercial electronics, aerospace as well as military and space applications. Call now!
Read More
Guide to Rheostats
Rheostats, a fundamental component in electrical engineering, play a crucial role in controlling current flow and adjusting resistance in electrical circuits. Call now!
Read More
Guide to Thick Film Resistors
Thick film resistors, hailed for their versatility, durability, and wide-ranging applications, are a cornerstone of modern electronics. Call now and request a quote!
Read More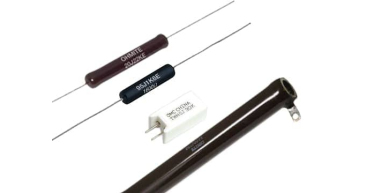
Guide to Wirewound Resistors
Thick film resistors, hailed for their versatility, durability, and wide-ranging applications, are a cornerstone of modern electronics. Call now and request a quote!
Read More
Ohms' Law Calculator
Read More
Ohm's Law 101
Ohm's Law stands as one of the fundamental principles in electrical engineering, providing a cornerstone for understanding and analyzing electrical circuits. Call now!
Read More
Energy Rating Calculator
Read More
Media Library
Read More
Industrial Resources
As a manufacturer of power resistors, Ohmite often creates products designed for industrial applications.
Read More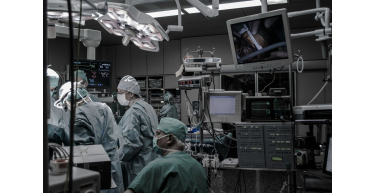
Medical Resources
As a manufacturer of power resistors, Ohmite often creates products designed for medical applications.
Read MoreTransportation Resources
As a manufacturer of power resistors, Ohmite often creates products designed for transportation applications.
Read More
Military & Aerospace Resources
As a manufacturer of power resistors, Ohmite often creates products designed for military and aerospace applications.
Read More